
Wikipedia does not have to be truthful, but it is important that the information must be confirmed by reliable sources. The last issue of the Wikimedia Research Showcase in outgoing 2020 was devoted to the problem of disinformation and the reliability of Wikipedia sources. This is a monthly public event that features the latest work from the Wikimedia Foundation’s Research Team and invited speakers from the academic community.
I was given the opportunity to talk about the latest scientific work carried out jointly with the members of our department. This article briefly describes the latest research of our department in the field of assessing the quality of information and the reliability of sources in the multilingual Wikipedia. Additionally, this article shows some of the tools for assessing quality and reliability based on scientific works.
The December 2020 issue of Wikimedia Research Showcase is available on YouTube, and slides from the presentation are posted on SlideShare and figshare.
Multilingual Wikipedia
According to Ethnologue, people in the world speak more than 7 thousand languages, of which almost 3 thousand are endangered. In comparison, Wikipedia articles are available in 319 languages.
More than half of the world’s population speaks only 23 languages. The most popular is English, it is spoken by about 1.27 billion people. However, for over 70% of them (including me 🙂 ), English is not native.
In my PhD thesis, which was defended in March 2019, I described a method for comparing and enriching information in multilingual wiki sites based on an analysis of their quality. The most popular wiki site, Wikipedia, was taken as an example. To test the proposed method, 5 language editions of Wikipedia were considered — Belarusian, English, Polish, Russian, Ukrainian.

An example of enriching the Belarusian Wikipedia with an infobox describing the Poznań University of Economics and Business. Source: PhD thesis
Knowledge of these languages and the results of research allowed me to conclude that the algorithms proposed in the dissertation can be used for other language versions of this free encyclopedia (as well as for other wiki sites).
Wikipedia can be edited in each language independently, which leads to problems such as:
- the same object (city, person, event, etc.) can be described in different ways,
- the user usually needs to understand these languages in order to check/compare information.
Additionally, the assessment of the quality of information itself is subjective and depends on the Wikipedia language:
- each language edition defines its own rules and standards,
- standards can change over time.
One of the important criteria for the quality of information on Wikipedia is the availability of reliable sources. However, the assessment of the same source depends on the language version of Wikipedia. An additional issue is that the reliability of the same source can change over time.
Assessing the quality of information on Wikipedia
Each language edition of Wikipedia may define its own quality rating system for articles. Often, each language version has a special mark for articles that are considered the best — “Featured Articles”. There is also a mark for quality, decent articles that do not meet the criteria for Featured Articles — they are called “Good Articles”.
Some language versions of Wikipedia also have other quality ratings that may reflect the “maturity” of an article. In the English Wikipedia, in addition to the highest marks “FA” and “GA”, there are also “A-class”, “B-class”, “C-class”, “Start” and “Stub”. In Russian Wikipedia, in addition to the two highest marks, there is also a “Solid article”, “I level”, “II level”, “III level” and “IV level”. The Polish Wikipedia has three additional classes: “Four”, “Start” and “Stub”.
Despite the same names, the equivalent classes between language versions may differ in how standards are evaluated. For example, in some language versions there is a limit on the length of the article for high marks. Therefore, each language version can have its own quality model, even if these languages have the same number of grades.
An additional problem is the large number of articles without quality assessment. Some language versions contain over 90% of articles without quality grade. Below is a comparative table for some language editions of Wikipedia (in order: Belarusian, German, English, French, Polish, Russian, Ukrainian).
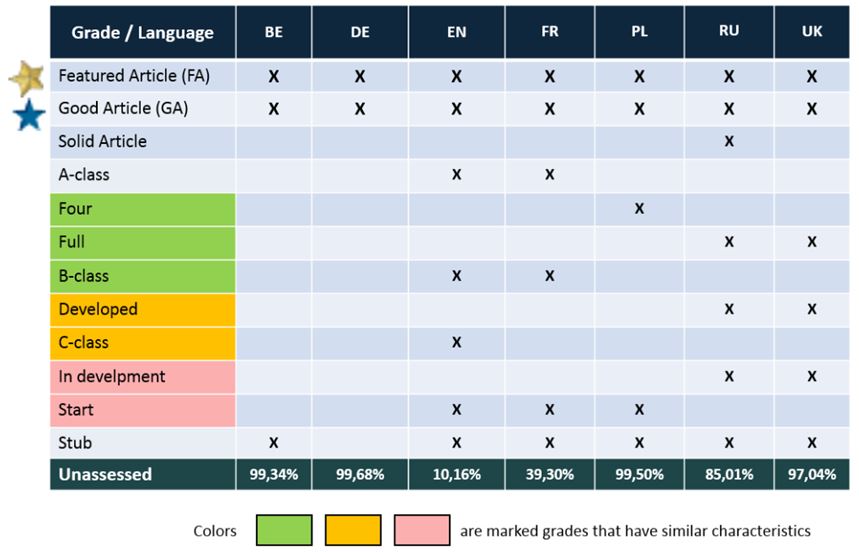
Quality classification in different language edition of Wikipedia. Source: Enrichment of Information in Multilingual Wikipedia Based on Quality Analysis (2017)
In order to define the quality dimensions in Wikipedia, one should take into account the similarity of this website with traditional encyclopedias and web 2.0 services. On the one hand, content in Wikipedia is created to be a reference point, in an encyclopedic style. On the other hand, Wikipedia is built in a way to allow collaboration between users. It is therefore based on web 2.0 technologies.
The figure below shows coverage between quality dimensions of the web 2.0, traditional encyclopedia and Wikipedia. Considering the quality criteria adopted by the Wikipedia community we can choose the following quality dimensions for the Wikipedia articles: completeness, credibility, objectivity, readability, relevance, style, timeliness.
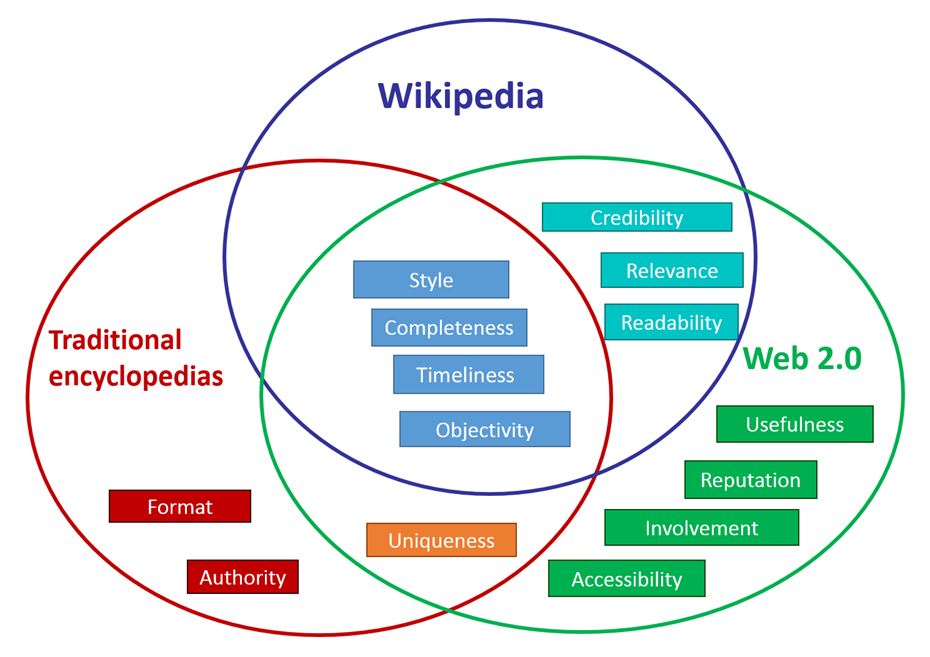
Coverage of the quality dimensions of three sources of information: traditional encyclopedias, Wikipedia, Web 2.0. Source: Measures for Quality Assessment of Articles and Infoboxes in Multilingual Wikipedia (2019)
- Credibility: whether the information provided can be checked with reliable sources.
- Completeness: how comprehensive the description of the topic is in article.
- Objectivity: to what extent the content of the article meets the criterion of a neutral point of view, does it contain pictures and other multimedia materials related to this article.
- Readability: to what extent the text is understandable and free from unnecessary complexity.
- Relevance: to what extent the article is relevant (important) for readers/users.
- Style: How the content of the article is organized.
- Timeliness: to what extent the article describes the current state of a certain reality (degree to which information is up-to-date).
Important quality measures
Using machine learning algorithms, we can determine which measures (indicators, features, parameter or characteristics) of Wikipedia articles are most important for assessing quality. An example of such parameters: the number of words in the text of the article, the number of images, visits to the article for a certain period of time, how many times the article was edited, etc.
Six years ago we published the results of research in which we showed that the indicators, together with their significance, form a certain profile of the language, that is, one parameter is important for one language, the other better characterizes the quality of information in another language version of Wikipedia. Then we can compare different languages.

Significance of measures depending on language. Source: Modelling the quality of attributes in Wikipedia infoboxes (2015)
Another example — in my PhD thesis, more than 100 features were used to build quality models for different languages. The figure below shows the importance of the selected metrics in the quality prediction models on the English and Russian Wikipedia.
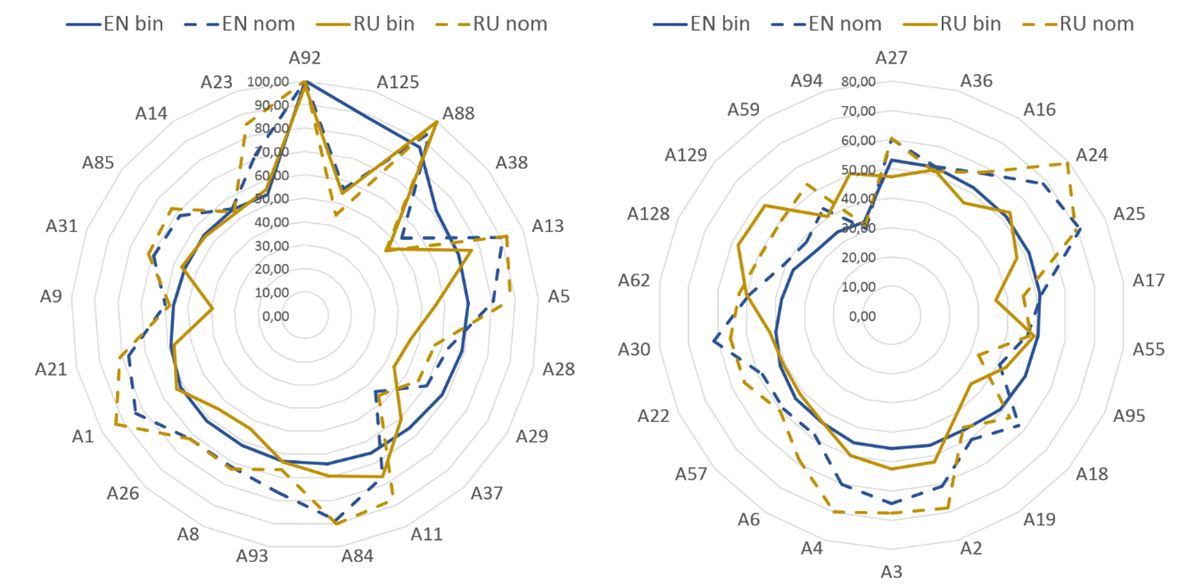
Significance of measures depending on language and model. Source: PhD thesis
Synthetic quality measure
We found that some of the metrics were highly important in assessing the quality of articles in different languages. Such parameters usually correlate positively with quality ratings: article length, number of images, notes (sources), sections, authors, etc.
Six years ago, we proposed a method for assessing article quality on a continuous scale (from 0 to 100) using a synthetic quality score that includes normalized values for important article parameters. The normalization of the selected options depends on the language edition of Wikipedia, as it uses thresholds that depend on the best articles in the language version in question. Normalization of each parameter was carried out in accordance with the following rule: if the value of this parameter in a given language exceeded the threshold value of the median value of the best articles in the same language version, it was taken equal to 100 points; otherwise, its value was scaled linearly to reflect the ratio of the parameter value to the mean. More detailed information about the algorithm and the results of its application of the synthetic quality index on millions of Wikipedia articles can be found in scientific publications in Informatics and Computers journal.
The numerical value of article quality allows comparing article quality even between different language versions of Wikipedia. This allows you to find which topics (categories) of articles in a particular language version of Wikipedia have better information.
Quality scores, together with indicators of popularity, citation, and author interest, can be used to create an individual profile for each Wikipedia article in each language version. For example, the picture below shows such a profile on the WikiRank portal with information on quality and popularity for the article “2020 United States presidential election (2020)” in English Wikipedia.
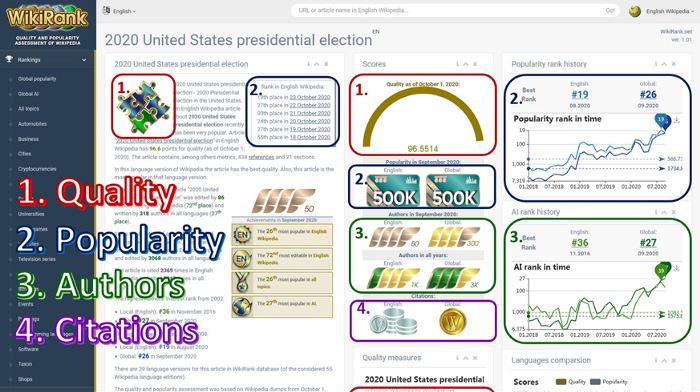
Implementation of the quality score on WikiRank.net
Sources of information on Wikipedia
One of the most important factors affecting the quality of Wikipedia articles is the availability of reliable sources. By following the links in the references (footnotes), readers can check facts or find more information on a topic described. In one of our recent papers, we analyzed over 40 million articles from the 55 most developed language versions of Wikipedia to extract information on over 200 million references and find the most popular and reliable sources.
In the aforementioned publication, we used different ways to find and extract information about the sources of Wikipedia articles. For example, complex extraction was based on the source code of the articles (wiki markup). The presence of some notes cannot be directly determined from the source (wiki) code of the articles. Sometimes information blocks or tables in a Wikipedia article are presented only as templates (links in code that allow you to get content from other Wikipedia pages). The figure shows this situation using the example of a table with links in the Wikipedia article on the coronavirus pandemic, which was added using a template. In our complex approach, we took into account the content of such templates.
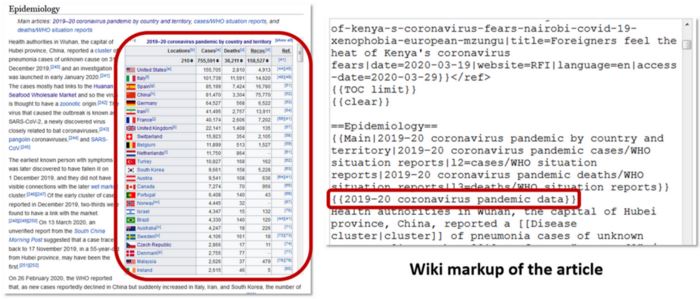
Table with references in the Wikipedia article about coronavirus pandemic that was added using template
The following figure shows the most commonly used “” tag patterns on the English Wikipedia. Among the most frequently used templates in the language versions of this Wikipedia are: ‘Cite web’, ‘Cite news’, ‘Cite book’, ‘Cite journal’ and others.
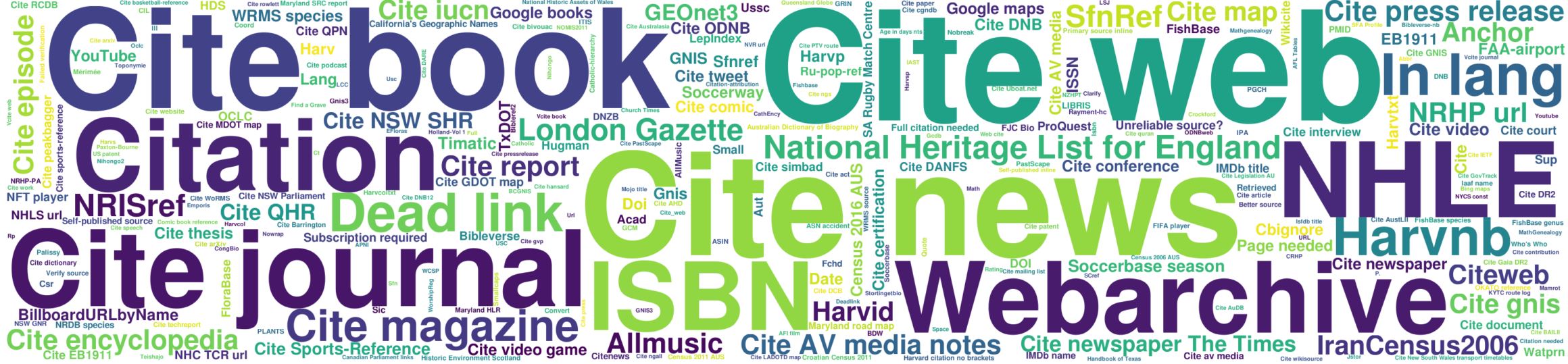
The most popular templates used in references in English Wikipedia. Source: Modeling Popularity and Reliability of Sources in Multilingual Wikipedia (2020)
For other language editions of Wikipedia, similar figures can be found in the supplementary materials to the scientific publication.
Citation templates
Some frequently used templates in notes describe the source in detail — they may contain information about authors, publisher, publication date, etc. For example, for the English Wikipedia, the most frequently filled parameters of such templates are shown in the figure:

The most frequently filled parameters in citation templates in English Wikipedia
For other language editions, the results of similar studies can be found on the page with additional materials.
After analyzing such templates with bibliographic data, we can find, for example, popular publishers on the English Wikipedia. With over 18 million of these templates, which have a value in the “publisher” parameter, a figure can be generated that shows the most frequently used publishers in the English Wikipedia sources.

The most commonly used names in publisher parameter of citations templates in English Wikipedia
Some of the most popular templates allow you to add identifiers to the source, such as DOI, JSTOR, PMC, PMID, arXiv, ISBN, ISSN, OCLC and others. Often such identifiers indicate a scientific source of information. The figure below shows which part of the notes in some language editions of Wikipedia contains information about sources with identifiers DOI, ISBN, ISSN, PMID, PMC.
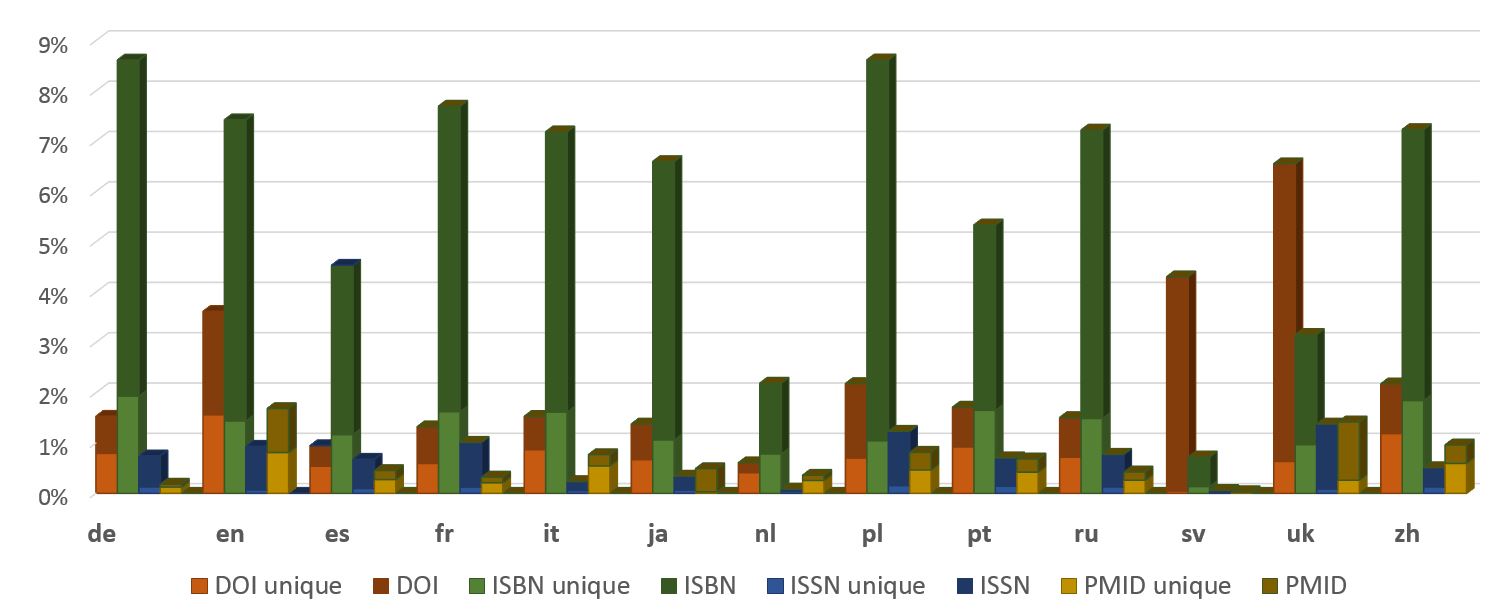
Wikipedia references with special identifiers (in percentages). Source: Modeling Popularity and Reliability of Sources in Multilingual Wikipedia (2020)
The results show that the most commonly used identifiers are ISBN and DOI. However, in the total number of references, there are no more than 10% of cases. It is important to note that there has been a gradual increase in the proportion of citations to scientific publications.
Popularity and reliability models of Wikipedia sources
In our recent research, we proposed ten models related to the popularity and reliability of sources. In most cases, source means the site (domain or subdomain) from the url in the references.
- F model — based on frequency (F) of source usage.
- P model — based on cumulative pageviews (P) of the article in which source appears.
- PR model — based on cumulative pageviews (P) of the article in which source appears divided by number of the references (R) in this article.
- PL model — based on cumulative pageviews (P) of the article in which source appears divided by article length (L).
- Models Pm, PmR, PmL are modified versions with daily pageviews median.
- Models A, AR, AL uses number of authors.
A more detailed description of the models (including the mathematical component) can be found in the publication.
Let’s look at the F model, which shows the frequency of use of the source, i.e. how often analyzed domain appears in the URL address of references. This method has often been used in related scientific work. Here we take into account the total number of occurrences of such a link, i.e. if the same source is quoted 3 times, we count the frequency as 3.
For the English Wikipedia, the most frequently used sites in the references are shown in the figure below:

The most popular and reliable sources in English Wikipedia using F-model. Source: Modeling Popularity and Reliability of Sources in Multilingual Wikipedia (2020)
If we look at the results of the source assessment based on the PR model, then the leaders on the English Wikipedia will look a little different:

The most popular and reliable sources in English Wikipedia using PR-model. Source: Modeling Popularity and Reliability of Sources in Multilingual Wikipedia (2020)
In the supplementary materials for the publication, you can find more extended results for different language versions using the F model and the PR model.
As we can see, depending on the model for assessing popularity and reliability, we can get different results for the same source. Studies have shown how different the credibility scores can also be, depending on the language version. Below is a comparative table of positions in the popularity and reliability rating for four sources: nytimes.com, spiegel.de, lemonde.fr, elpais.com. Each source was assessed in terms of different language edition of Wikipedia and different models.
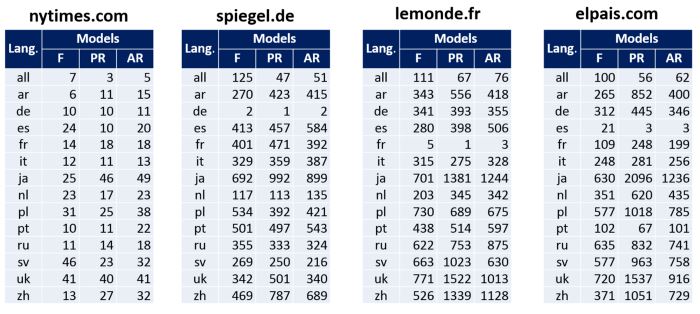
Positions in the popularity and reliability ratings of the sources in Wikipedia
If we consider sites (domains) as sources, then their number reaches more than a million. Part of the results for the evaluation of each Wikipedia source is posted in the BestRef project. For each source in this project, there is a separate profile that shows the results of the assessment using different models and within each language version of Wikipedia. For the above four sources, these are nytimes.com, spiegel.de, lemonde.fr, elpais.com, respectively. Separately, you can see the list of the most popular and reliable sources within a specific language edition (for example, English Wikipedia). Below is an example of a list of sources and a profile for an individual site.
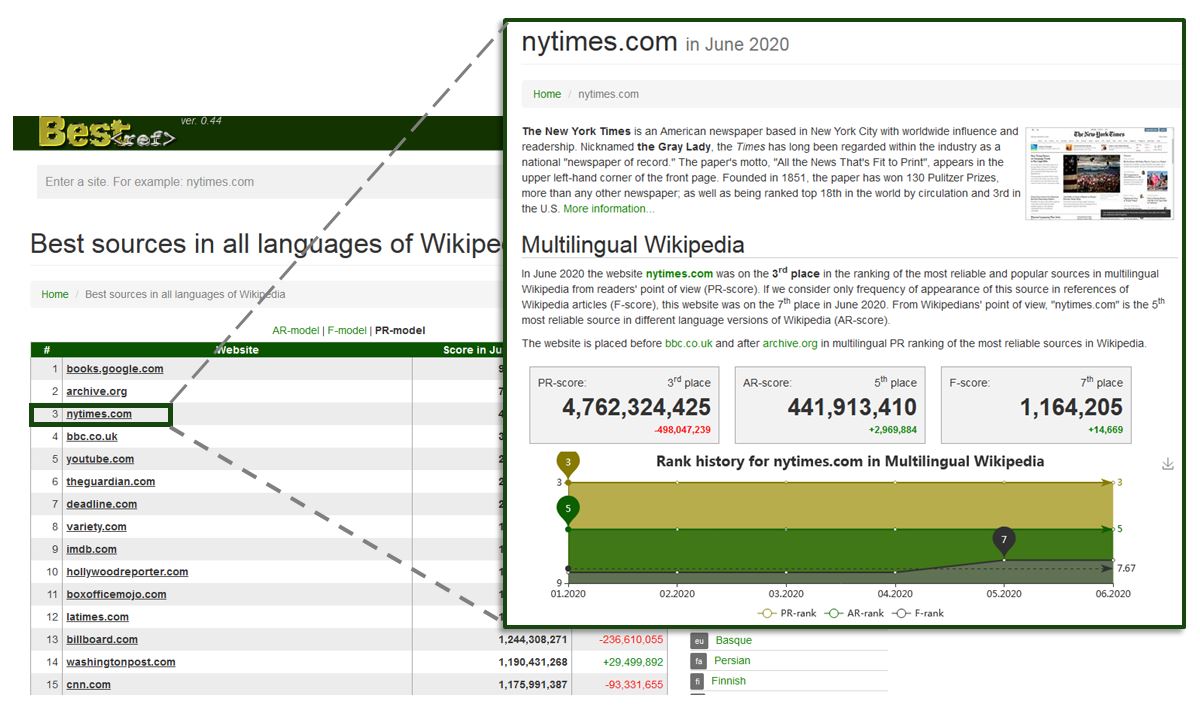
List of sources and profile on BestRef.net
Using different models of popularity and reliability, we can evaluate not only domains, but also certain types of sources. For example, based on extensive bibliographic information from templates in footnotes, we ranked all publishers on the English Wikipedia sources. The table below shows the most popular and reliable publishers with ranking positions by model.
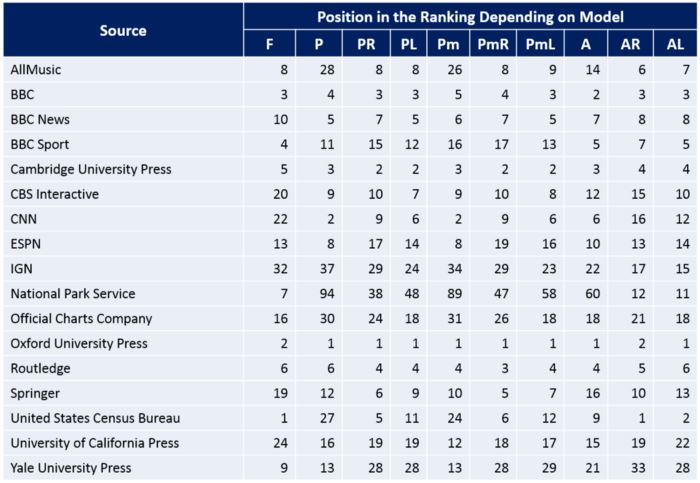
Publishers in references and their rank on English Wikipedia using different models. Source: Modeling Popularity and Reliability of Sources in Multilingual Wikipedia (2020)
Tools for quality and reliability assessment
The results of some of the studies were incorporated into separate public projects. Moreover, there are even browser extensions that allow you to research the quality of Wikipedia articles and their sources “in place”. For example, you can use the BestRef plugin for Chrome to investigate the credibility of sources. Video presentation of this plugin:
You can use the WikiRank plugin for Chrome and Firefox to rate and compare the quality and popularity of Wikipedia articles. Briefly how it works is shown in this video.
An extension is available separately for assessing the quality of infoboxes (information cards) in the Chrome browser. You can learn how it works on the video presentation.
What’s next?
The considered models of information quality, popularity and credibility of sources can help to enrich various language versions of Wikipedia and other knowledge bases (such as DBpedia, Wikidata) with higher quality information. Some of the methods are planned to be integrated into the GlobalFactSync (GFS) project. The goal of the GFS project is to synchronize factual data across all language chapters of Wikipedia and Wikidata. Here, factual data is defined as a specific “chunk” of information, that is, data values such as “geographic coordinates”, “population” (for cities), “date of birth”, “chemical formulas”, “participation in films” or “place of birth” attached to an object (in a Wikipedia article or Wikidata item) and ideally with a reference to the source (the origin of this information).
Additionally, information about the reliability of sources can help to improve models for quality assessment of Wikipedia articles. This can be especially useful when comparing inconsistent facts between language versions of Wikipedia articles. In addition, one of the promising areas of upcoming research is the creation of publicly available tools that would make it possible to recommend the best sources for individual statements and on selected topics in different language versions of Wikipedia.
The models proposed in the research are not ideal and can be improved — there is a “huge field for maneuvers”. The more we investigate this area, the more we find problems and possible solutions.
More information on research in this field can be found on the WikiQ project. If you are interested in this topic, we are ready to consider cooperation in this direction. Questions and suggestions can be left here in the comments or feel free to contact me in another way.
References
- Hellmann S., Johannes F., Hofer M., Dojchinovski M., Węcel K., Lewoniewski W. (2021). Towards a Systematic Approach to Sync Factual Data across Wikipedia, Wikidata and External Data Sources. Conference QURATOR 2021.
- Lewoniewski, W., Węcel, K., Abramowicz, W. (2020). Modeling Popularity and Reliability of Sources in Multilingual Wikipedia. Information, 11(5), 263. DOI: 10.3390/info11050263
- Lewoniewski, W., Węcel, K., Abramowicz, W. (2019). Multilingual Ranking of Wikipedia Articles with Quality and Popularity Assessment in Different Topics. Computers, 8(3), 60. DOI: 10.3390/computers8030060
- Lewoniewski, W. (2019). Measures for Quality Assessment of Articles and Infoboxes in Multilingual Wikipedia. In International Conference on Business Information Systems (pp. 619–633). Springer, Cham. DOI: 10.1007/978-3-030-04849-5_53
- Lewoniewski, W. (2018). The method of comparing and enriching information in multilingual wikis based on the analysis of their quality. PhD thesis
- Lewoniewski, W., Węcel, K., Abramowicz, W. (2017). Relative Quality and Popularity Evaluation of Multilingual Wikipedia Articles. Informatics 2017, 4(4), 43. DOI: 10.3390/informatics4040043
- Lewoniewski, W. (2017). Enrichment of Information in Multilingual Wikipedia Based on Quality Analysis. In International Conference on Business Information Systems (pp. 216–227). Springer, Cham. DOI: 10.1007/978-3-319-69023-0_19
- Lewoniewski, W., Węcel, K., Abramowicz, W. (2017). Analysis of references across Wikipedia languages. In International Conference on Information and Software Technologies (pp. 561–573). Springer, Cham. DOI: 10.1007/978-3-319-67642-5_47
- And other scientific publications on Wikipedia quality.
Source: medium.com